
Duplicate code quietly undermines software projects, creating maintenance headaches and introducing subtle bugs that compound over time. When the same logic appears in multiple places, a single fix requires tracking down every instance, and missed updates lead to inconsistent behavior. This guide equips you with proven methods to identify duplicate code across all complexity levels, from exact matches to semantic clones that share intent but differ in implementation. You'll learn practical detection techniques, tool selection strategies, and workflow integration approaches that transform code quality from reactive cleanup to proactive prevention.
Table of Contents
- Understanding Duplicate Code And Its Types
- Preparing To Detect Duplicates: Selection And Setup Of Tools
- Executing Duplicate Code Detection Step-By-Step
- Verifying Results And Integrating Duplicate Detection Into Workflows
- Streamline Your Duplicate Code Detection With VibeDoctor
- FAQ
Key takeaways
| Point | Details |
|---|---|
| Four clone types exist | Type-1 through Type-4 clones range from exact copies to semantic duplicates with different syntax but similar functionality. |
| Detection methods vary | Token-based tools scale well for simple clones, while ML and AI approaches excel at finding semantic duplicates. |
| Integration prevents spread | Embedding detection in CI/CD pipelines catches duplicates before they reach production and multiply across codebases. |
| Classification drives action | Identifying whether duplication is exact, near, or semantic helps prioritize fixes and avoid wasting effort on intentional patterns. |
| Measurable quality gains | Projects typically achieve 3-5% code reduction after automated refactoring, with improved maintainability and fewer bugs. |
Understanding duplicate code and its types
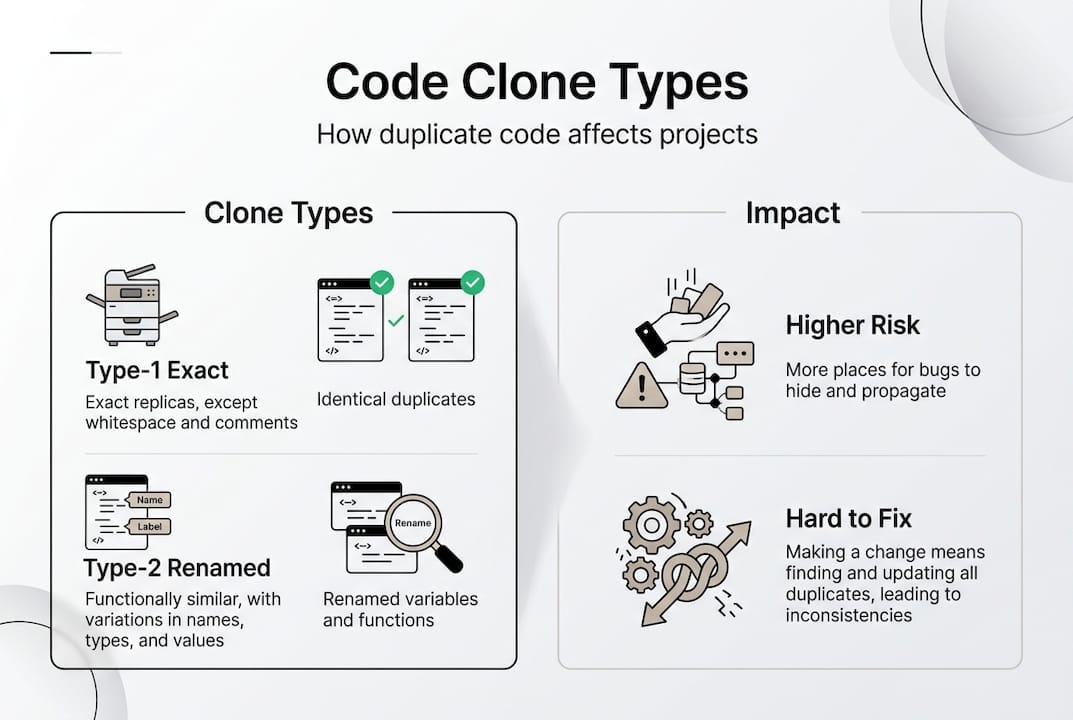
Duplicate code appears in four distinct forms, each presenting unique detection challenges. Code clones are classified into four types: Type-1 clones are exact matches differing only in whitespace or comments, Type-2 clones involve parameterized changes to identifiers or literals, Type-3 clones include statement-level modifications like added or removed lines, and Type-4 clones represent semantic duplicates with similar functionality but completely different syntax. Recognizing these categories matters because detection difficulty increases dramatically from Type-1 to Type-4, with semantic clones requiring sophisticated analysis beyond simple text comparison.
Type-1 clones emerge when developers copy and paste code blocks without modification, leaving identical logic scattered across files. A function calculating tax rates might appear verbatim in three different modules, differing only in spacing or comment style. Type-2 clones introduce variable name changes or different literal values while preserving structure. The same validation logic might check "userEmailin one location andcustomerEmail` elsewhere, with identical conditional flow but renamed identifiers.
Type-3 clones involve more substantial modifications where developers add logging statements, reorder operations, or insert new conditionals into copied code. A payment processing function might exist in two forms, one with additional error handling and another with performance optimizations, yet both share core logic. Type-4 clones represent the hardest challenge: two functions achieving the same goal through entirely different approaches, like one using recursion while another uses iteration to traverse a data structure.
| Clone Type | Characteristics | Detection Difficulty | Common Example | | --- | --- | | Type-1 | Exact copies, whitespace/comment differences only | Low | Copy-pasted utility functions | | Type-2 | Renamed identifiers, different literals | Low to Medium | Validation logic with different variable names | | Type-3 | Statement modifications, added/removed lines | Medium to High | Enhanced versions of original functions | | Type-4 | Semantic similarity, different implementation | Very High | Alternative algorithms for same task |
The impact on maintainability grows exponentially with clone count and type complexity. Type-1 duplicates create obvious maintenance burden since every bug fix requires manual tracking of all instances. Type-4 clones hide in plain sight, causing logic drift where similar functionality evolves independently, creating inconsistent behavior across your application. When security vulnerabilities surface in duplicated authentication code, teams must locate and patch every variant, and missing even one instance leaves an exploitable gap.
Preparing to detect duplicates: selection and setup of tools
Choosing the right detection approach depends on your project's language ecosystem, clone types you need to catch, and integration requirements. Detection methods include text/token-based tools that scale well but struggle with semantics, tree-based AST analyzers better suited for Type-1 through Type-3 clones, graph-based approaches for architectural patterns, and ML/LLM solutions like CodeBERT or UniXCoder that excel at semantic detection. Commercial options like CodeAnt AI and SonarQube offer comprehensive coverage, while open source tools like PMD CPD and jscpd provide focused capabilities for specific languages.
Token-based detection works by converting code into sequences of meaningful units, then comparing these sequences for similarity. These tools run fast and handle large codebases efficiently, making them ideal for initial scans and continuous integration checks. However, they miss semantic clones entirely and generate false positives on templated code or common patterns. AST-based analyzers parse code into abstract syntax trees, comparing structural patterns rather than raw text. This approach catches Type-2 and Type-3 clones more reliably and reduces noise from formatting differences.
Graph-based methods model code as networks of dependencies, identifying duplicated architectural patterns and control flow structures. These tools shine when detecting cloned subsystems or duplicated design patterns across modules. ML and AI approaches leverage trained models to understand code semantics, recognizing when two functions accomplish the same goal despite different implementations. CodeBERT and UniXCoder have demonstrated strong performance on Type-4 clones, though they require more computational resources and careful tuning.
Integrating detection into your development workflow prevents duplication from spreading. Configure tools to run on every pull request, blocking merges when new duplicates exceed your threshold. Set up nightly scans for deeper analysis using computationally intensive methods. Connect findings to your issue tracker so teams can prioritize refactoring alongside feature work. Many projects combine fast token-based checks in PR pipelines with weekly ML-powered scans for semantic clones.

Pro Tip: Run multiple detection methods in parallel rather than relying on a single tool. Token-based scanners catch obvious duplicates quickly, while periodic ML analysis surfaces hidden semantic clones that simpler tools miss. This layered approach balances speed with thoroughness.
When selecting tools, consider your team's language stack and existing infrastructure. JavaScript projects benefit from jscpd's npm integration, while Java codebases leverage PMD CPD's Maven and Gradle plugins. Python teams often combine Pylint with automated code checks that scan for duplication alongside other quality metrics. Cross-language projects need tools supporting multiple syntaxes, making SonarQube or commercial platforms more practical than language-specific analyzers.
Executing duplicate code detection step-by-step
Running detection effectively requires a systematic approach that moves from initial scanning through classification to prioritized action. Start by configuring your chosen tool with appropriate thresholds: set minimum token counts or similarity percentages that balance sensitivity against noise. Lower thresholds catch more duplicates but increase false positives, while higher thresholds miss borderline cases. Most teams find 50-70% similarity thresholds work well for initial scans, then adjust based on results.
- Execute your detection tool against the target codebase, starting with a single module or package to validate configuration before scaling to the entire project.
- Review the generated report, sorting findings by severity based on duplication size, frequency, and location in critical paths.
- Classify each detected duplicate as exact, near, or semantic to determine the appropriate resolution strategy.
- Filter out intentional duplicates like configuration templates, generated code, or deliberately isolated implementations.
- Create refactoring tickets for validated duplicates, prioritizing those in frequently modified files or security-sensitive modules.
- Verify fixes by re-running detection to confirm duplication reduction without introducing new clones elsewhere.
Handling hidden duplicates requires attention to edge cases that confuse automated tools. Semantic clones remain the hardest challenge, as Type-4 duplicates share intent but not structure, requiring human judgment to confirm. Cross-repository duplication spreads when teams copy code between projects, creating maintenance nightmares that single-repo scans miss entirely. AI-generated code introduces new patterns where multiple developers prompt similar functionality, producing structurally different but semantically identical implementations.
False positives emerge from legitimate code patterns that resemble duplication. Template code, boilerplate required by frameworks, and generated files like protocol buffers or database schemas trigger detection tools despite serving distinct purposes. Classify these findings before investing refactoring effort: exact duplicates warrant immediate extraction into shared functions, near duplicates might benefit from parameterization, and semantic duplicates require careful analysis to determine if consolidation improves or harms the design.
Some duplication serves valid architectural purposes. Latency-sensitive services sometimes duplicate logic to avoid cross-service calls that add milliseconds to response times. Security-critical validation might exist in multiple layers as defense in depth, where removing duplication creates single points of failure. Domain-driven design deliberately duplicates concepts across bounded contexts to maintain independence. Accept these intentional duplicates by documenting the rationale and excluding them from future scans.
| Tool | Strengths | Best For | Limitations |
|---|---|---|---|
| PMD CPD | Fast token-based detection, multi-language | CI/CD pipelines, large codebases | Misses semantic clones |
| SonarQube | Comprehensive quality metrics, enterprise features | Teams needing unified quality platform | Commercial licensing for advanced features |
| jscpd | JavaScript/TypeScript focus, simple setup | Frontend projects, quick scans | Single-language limitation |
| CodeBERT | ML-powered semantic detection | Type-4 clones, research projects | Requires GPU resources, slower execution |
Common mistakes include running detection once and forgetting it, treating all duplicates equally regardless of impact, and refactoring without understanding why duplication occurred. Teams waste effort extracting trivial duplicates that add more complexity than they remove. Focus detection on high-change areas where duplication causes real pain: frequently modified business logic, security-critical paths, and modules with high bug rates.
Pro Tip: Configure pull request checks to flag new duplicates that cross repository boundaries. This prevents developers from copying code between microservices or packages, catching architectural problems before they spread across your entire system.
Troubleshooting detection issues often involves tuning sensitivity parameters. If scans return thousands of findings, raise minimum token counts or similarity thresholds to focus on substantial duplicates. When known duplicates go undetected, lower thresholds or switch to AST-based analysis that catches structural similarities missed by token comparison. For semantic clones, invest in ML-powered tools or supplement automated detection with automated checks overview that combine multiple analysis techniques.
Verifying results and integrating duplicate detection into workflows
Validating detection accuracy prevents wasted refactoring effort on false positives and ensures real duplicates get addressed. After running detection, manually review a sample of findings across different similarity scores to assess precision. Check whether flagged code truly represents duplication or legitimate patterns. Compare detection results against your team's intuition about problem areas: if scans miss known duplicates, adjust tool configuration or try alternative detection methods. Track metrics before and after refactoring to quantify impact on codebase size, test coverage, and bug rates.
Duplicate detection performance varies significantly across models and clone types. Large language models achieve F1 scores of 0.94 on datasets like CodeNet but show reduced accuracy on BigCloneBench's diverse clone patterns. Smaller specialized models like PLBART reach 0.905 F1 on BigCloneBench, while Rator exceeds 99% F1 across all clone types. Real-world codebases typically see 3-5% reduction in total lines after automated refactoring, with the largest gains in projects that had accumulated technical debt. Tools like ECScan demonstrate 85% F1 on essence clones, showing that targeted approaches can match or exceed general-purpose models for specific duplication patterns.
Integrating detection into continuous integration catches duplicates at creation time rather than discovering them months later. Configure your CI pipeline to run token-based scans on every commit, failing builds when new duplicates exceed team-defined thresholds. Schedule nightly or weekly deep scans using computationally intensive methods that identify semantic clones. Connect detection results to code review tools so reviewers see duplication warnings alongside other feedback. This shift-left approach prevents duplication from entering the codebase rather than cleaning it up after the fact.
- Add duplication metrics to your team dashboard alongside test coverage and bug counts, making code quality visible to all stakeholders.
- Set up automated tickets when scans detect duplicates above severity thresholds, routing them to appropriate team members based on file ownership.
- Establish refactoring sprints quarterly to address accumulated duplication debt that automated checks flagged but teams deferred.
- Create exemption processes for intentional duplicates, documenting architectural decisions and excluding known patterns from future scans.
- Train new team members on duplication detection as part of onboarding, ensuring everyone understands how to interpret findings and when to refactor.
Pro Tip: Monitor duplication trends over time rather than focusing on absolute numbers. A gradual increase signals process problems where new duplicates appear faster than teams can refactor, while steady reduction indicates effective integration of detection into development workflows.
| Model/Tool | F1 Score | Dataset | Clone Types Covered |
|---|---|---|---|
| Large LLMs | 0.94 | CodeNet | Type-1 through Type-4 |
| PLBART | 0.905 | BigCloneBench | Type-1 through Type-3 |
| Rator | >0.99 | BigCloneBench | All types |
| ECScan | 0.85 | Essence clones | Semantic (Type-4) |
Aligning detection with broader code quality goals ensures duplication reduction serves your team's actual needs. If deployment frequency matters most, prioritize removing duplicates in CI/CD scripts and deployment automation. For security-focused projects, concentrate on duplicated authentication, authorization, and input validation logic. High-reliability systems benefit from eliminating duplicates in error handling and recovery paths where inconsistent behavior causes outages.
Continuous monitoring maintains gains after initial cleanup. Schedule monthly reviews of duplication metrics to catch regression. Celebrate teams that reduce duplication in their modules, creating positive reinforcement for quality-focused development. Share examples of bugs prevented or maintenance simplified by eliminating duplicates, making the business value tangible. Integrate automated code quality checks that provide ongoing visibility into duplication alongside other quality dimensions.
Streamline your duplicate code detection with VibeDoctor
Maintaining clean, duplication-free code requires consistent monitoring and comprehensive analysis across your entire codebase. VibeDoctor offers cutting-edge duplicate code detection as part of its 15-point diagnostic platform, combining AI-powered semantic analysis with traditional detection methods to catch clones at every complexity level. By connecting your GitHub repository, you receive instant insights into code smells, duplicate patterns, and quality issues without granting modification access.
The platform integrates duplicate detection with security scanning, performance analysis, and deep code quality checks, giving you a complete picture of application health. Real-time feedback through IDE integration via MCP means you catch duplicates as you write code, not weeks later during refactoring sprints. Explore the full suite of VibeDoctor automated checks to see how comprehensive analysis transforms code quality, or visit the VibeDoctor AI code scanner to start your free diagnostic today.
Pro Tip: Leverage continuous scanning to maintain code quality gains over time. Regular automated checks prevent duplication from creeping back into your codebase as teams add features and fix bugs.
FAQ
What are the main types of duplicate code clones?
Duplicate code falls into four categories based on similarity level. Type-1 clones are exact copies differing only in whitespace or comments, while Type-2 clones involve renamed identifiers or changed literals. Type-3 clones include statement-level modifications like added or removed lines, and Type-4 clones represent semantic duplicates with completely different syntax but similar functionality. Higher types become progressively harder to detect, with Type-4 requiring sophisticated semantic analysis.
Which detection method works best for semantic duplicates?
Machine learning and AI-based tools like CodeBERT and UniXCoder perform best for semantic clones by understanding code intent rather than just structure. These models analyze functionality and purpose, catching Type-4 duplicates that token-based methods miss entirely. Token-based and AST approaches lack the semantic insight needed to recognize when two functions accomplish the same goal through different implementations, making ML tools essential for comprehensive duplicate detection.
How can I reduce false positives when detecting duplicates?
Exclude generated code, framework boilerplate, and template files from scans to eliminate noise from legitimate patterns. Classify detected duplicates by type before taking action, focusing effort on exact and near matches that clearly warrant refactoring. Combine automated checks strategies with manual review to validate findings, especially for borderline cases where structural similarity might not indicate true duplication. Adjust detection thresholds based on your codebase characteristics, raising minimums if scans return too many trivial matches.
What benefits can I expect after fixing duplicate code?
Codebases typically achieve 3-5% reduction in total lines after automated refactoring, with larger gains in projects carrying significant technical debt. Beyond size reduction, you'll see improved maintainability as bug fixes and feature changes require updating fewer locations. Reduced duplication lowers bug risk by eliminating inconsistencies where copied code evolves differently across instances, and teams report faster development velocity once common logic consolidates into reusable components.